ディープラーニングでバドミントンのコートを検知できるかやってみました。OpenCV等を用いた画像処理でテニスコートを検知する方法はよく見かけるのですが、光の具合や人がコートに被るなどの問題、それに、球が高く上がる関係上どうしてもコート外 (観客席等) が映ってしまうという、テニスにはない、バドミントン特有の問題があり、汎用的なものをつくるにはかなり難しいと思います。これらをディープラーニングで解決できるのか、見ていきたいと思います。
手法は下記のサイトのface landmark detectionを参考にしました。こちらでは、resnetの出力の次元を132にし、それを顔の64個の点に対応させています (64×2=132)。それと同様に、コートの画像とコート上の16点の座標を用意し、resnetで学習しました。
https://thecleverprogrammer.com/2020/07/22/face-landmarks-detection/
学習データセットの準備
画像はBWFのYouTube動画をスクリーンショットし、50枚用意しました (少ないですね)。正解データの作成にははhttps://github.com/donydchen/landmark-toolを使わせていただきました。下の画像のように、各コート画像に16点のデータを付与していきます。
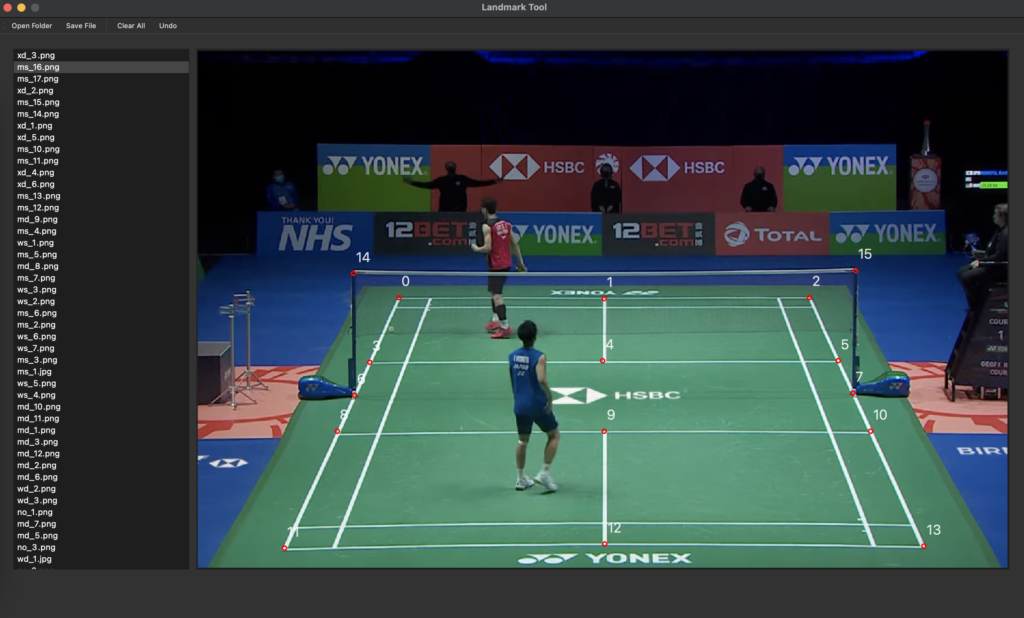
landmark-toolにqt5対応と点のインデックスを表示するようにカスタマイズしています。利用する場合は以下のパッチをあててください。https://github.com/daikon-oroshi/court-detection-sample/blob/master/landmark-tool.patch
$ patch -p1 -d landmark-tool < landmark-tool.patch学習モデル
モデルはresnetの出力をoutput_size (今回は32) にしたものを使用しました。 当たり前ですがresnet152の方がresnet18より精度が高いですね。データが少なく学習時間にそれほど差がなかったのでresnet152を使いました。
class Net(nn.Module):
def __init__(self, output_size, pretrained=True, grayscale=False):
super(Net, self).__init__()
resnet = torchvision.models.resnet152(pretrained=pretrained)
# resnet = torchvision.models.resnet18(pretrained=pretrained)
num_ftrs = resnet.fc.in_features
self.resnet_base = nn.Sequential(*list(resnet.children())[:-1])
self.fc = nn.Linear(num_ftrs, output_size)
def forward(self, x):
h = self.resnet_base(x)
h = h.view(h.size(0), -1)
h = self.fc(h)
return hデータ拡張
データ読み込み時にランダムで左右反転とRandom Erasingをさせました。左右反転は単にデータの水増し、Random Erasingはコートの構造上、一部をマスクしても推測できるべきであるという理由で入れました。Random Erasingを入れた方が若干精度が良くなります。

class HorizontalFlip:
def __init__(
self,
p: float = 0.5
):
self.p = p
def mirror(self, x: float) -> float:
return -x
def flip_landmarks(self, landmarks):
mirror_lmarks = list(map(
lambda x: [self.mirror(x[0]), x[1]],
landmarks
))
lmarks = []
# 2 <-> 0
lmarks.append(mirror_lmarks[2])
lmarks.append(mirror_lmarks[1])
lmarks.append(mirror_lmarks[0])
# 3 <-> 5
lmarks.append(mirror_lmarks[5])
lmarks.append(mirror_lmarks[4])
lmarks.append(mirror_lmarks[3])
# 6 <-> 7
lmarks.append(mirror_lmarks[7])
lmarks.append(mirror_lmarks[6])
# 8 <-> 10
lmarks.append(mirror_lmarks[10])
lmarks.append(mirror_lmarks[9])
lmarks.append(mirror_lmarks[8])
# 11 <-> 13
lmarks.append(mirror_lmarks[13])
lmarks.append(mirror_lmarks[12])
lmarks.append(mirror_lmarks[11])
# 14 <-> 15
lmarks.append(mirror_lmarks[15])
lmarks.append(mirror_lmarks[14])
return lmarks
def __call__(self, sample) -> t.Tuple:
if random.random() > self.p:
return sample
else:
fliped = sample['image'].transpose(PIL.Image.FLIP_LEFT_RIGHT)
lmarks = self.flip_landmarks(sample['landmarks'])
return {
'image': fliped,
'landmarks': lmarks
}
class RandomErasing:
def __init__(
self,
p=0.5,
scale=(0.02, 0.33),
ratio=(0.3, 3.3),
value=0, inplace=False
):
self.transform = torchvision.transforms.RandomErasing(
p=p, scale=scale, ratio=ratio, value=value, inplace=inplace
)
def __call__(self, sample):
to_tensor = torchvision.transforms.ToTensor()
to_pil = torchvision.transforms.ToPILImage()
transed_tensor = self.transform(to_tensor(sample['image']))
transed_pilim = to_pil(transed_tensor).convert("RGB")
return {
'image': transed_pilim,
'landmarks': sample['landmarks']
}学習
各点の正解との距離の平均二乗誤差をloss関数とし、それを最小化するように学習させました。距離の2乗なので、2次元×16点と思って計算しても32次元の点として誤差を計算しても同じです(普通の距離を誤差関数にすると各点ごとに計算する必要があります)。コードはpytorchの公式サンプルを少しいじったものになっています。
def create_dataloader(img_paths: str, land_path: str, batch_size=4):
phase = ['train', 'val']
size = (224, 224)
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
data_transforms = {
phase[0]: torchvision.transforms.Compose([
Resize(size),
RandomErasing(scale=(0.02, 0.15)),
HorizontalFlip(),
ToTensor(),
Normalize(norm_mean, norm_std)
]),
phase[1]: torchvision.transforms.Compose([
Resize(size),
ToTensor(),
Normalize(norm_mean, norm_std)
]),
}
image_datasets = {
x: BdcDataSet(
os.path.join(img_paths, x),
land_path,
data_transforms[x]
) for x in phase
}
dataloaders = {
x: torch.utils.data.DataLoader(
image_datasets[x], batch_size=batch_size,
shuffle=True, num_workers=1
) for x in phase
}
dataset_sizes = {x: len(image_datasets[x]) for x in phase}
return dataloaders, dataset_sizes
def train(
device,
net,
criterion,
optimizer,
scheduler,
dataloaders,
dataset_sizes,
num_epochs=25
):
since = time.time()
best_model_wts = copy.deepcopy(net.state_dict())
best_loss = None
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
net.train() # Set model to training mode
else:
net.eval() # Set model to evaluate mode
running_loss = 0.0
# Iterate over data.
for td in dataloaders[phase]:
inputs = td['image'].to(device)
labels = td['landmarks'].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
loss = criterion(outputs.float(), labels.float())
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / dataset_sizes[phase]
print('{} Loss: {:.4f}'.format(phase, epoch_loss))
if phase == 'train':
print('LR: {}'.format(optimizer.param_groups[0]['lr']))
if scheduler is not None:
scheduler.step()
# deep copy the model
if phase == 'val':
if not math.isnan(epoch_loss) and \
(best_loss is None or best_loss > epoch_loss):
best_loss = epoch_loss
best_model_wts = copy.deepcopy(net.state_dict())
if best_loss is not None:
print('BEST Loss: {:.4f}'.format(best_loss))
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Loss: {:4f}'.format(best_loss))
# load best model weights
net.load_state_dict(best_model_wts)
return net
if __name__ == "__main__":
img_path = sys.argv[1]
land_path = sys.argv[2]
save_path = sys.argv[3]
net = model.Net(32, grayscale=False)
net.to('cpu')
dataloaders, dataset_sizes = model.create_dataloader(
img_path, land_path, 8)
learning_rate = 1e-4
optimizer_ft = torch.optim.Adam(net.parameters(), lr=learning_rate)
criterion = torch.nn.MSELoss()
scheduler = None
model_tr = train(
'cpu',
net,
criterion,
optimizer_ft,
scheduler,
dataloaders,
dataset_sizes,
num_epochs=50
)
torch.save(model_tr.state_dict(), save_path)結果
validationで用いた画像での結果はこんな感じです。

一応学習に用いた画像だとこんな感じです。

あまり良いとは言えない結果ですね。face landmark detectionのサンプルの精度を見るとこんなものかという感じもしますが、もう少し上手くいく気がしてました。データが少なすぎるのと2乗誤差がシンプルすぎるのが原因でしょうか。
まとめ
face landmark detectionの手法としてはheatmapで推定する方法や他にも色々な手法があるので、試してみようと思います。また、コート検知の特徴として、直線上に推測する点が並ぶということが挙げられます。これを考慮したloss関数をうまく作るのも重要だと思われます。標準サイズのコートへの射影変換を推測させるのはどうでしょうか。色々工夫のしがいがあるので、試してみようと思います。
コードはgithubにアップしてます。 https://github.com/daikon-oroshi/court-detection/tree/v1
ご支援のお願い
記事を読んで、「支援してもいいよ」と思っていただけましたら、ご支援いただけると幸いです。サーバー維持費などに充てさせていただきます。登録不要で、100円から寄付でき、金額の90%がクリエイターに届きます。